이전에 「*」을 사용하는 전통적 포인터 개념을 복습했다.
하지만 요즘의 C++ 프로젝트에선 스마트 포인터가 대세가 된 지 오래.
언리얼 엔진도 소스코드를 들여다보면 스마트 포인터로 가득하다.
정말 중요한 개념이라 할 수 있는 스마트 포인터에 대해 복습해 보자.
1. 스마트 포인터의 필요성
먼저 기존의 포인터를 사용하는 환경을 아래와 같은 코드로 구성했다.
#include <iostream>
class Player
{
public:
Player()
{
std::cout << "Constructor" << std::endl;
}
~Player()
{
std::cout << "Destructor" << std::endl;
}
void Attack()
{
if (_tgt)
{
_tgt->_hp -= _dmg;
std::cout << "Target's HP : " << _tgt->_hp << std::endl;
}
}
public:
int _hp = 100;
int _dmg = 10;
Player* _tgt = nullptr;
};
int main()
{
Player* p1 = new Player();
Player* p2 = new Player();
p1->_tgt = p2;
delete p2;
p1->Attack();
return 0;
}
p1이 p2를 타겟으로 잡고 p2를 공격하려는 찰나 p2가 사라져 버렸다.
이 코드를 실행하면 p2가 사라졌으니 nullptr이 되어 에러가 발생할 것이라고 유추할 수 있다.
실행시켜 보자.
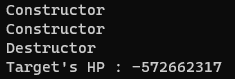
실행 결과 예상과 다르게 에러는 나지 않았지만, p2의 hp가 이상하게 표현된다.
p2가 사라졌다고 해서 p1이 갖고 있는 p2의 정보가 갱신되지 않기 때문이다.
p1의 _tgt는 여전히 p2가 원래 있던 그 주소를 참조하고 있기 때문에 이상한 값을 출력할 수밖에 없는 것이다.
지금은 사용하지 않는 메모리 영역이라 큰 문제가 생기지 않았지만,
p2 삭제 직후 새로운 메모리가 그 자리에 할당되었다면 큰 문제가 발생할 수밖에 없다.
프로젝트가 커진다면 저 실수 하나 때문에 모든 게 난리가 날 수 있다.
그렇기에 우리는 메모리 오염을 방지하기 위해 스마트 포인터를 사용해야 하는 것이다.
2. 스마트 포인터의 구조와 동작
스마트 포인터는 포인터를 일정한 Policy에 따라 관리를 하는 별도의 객체라고 할 수 있다.
기존의 포인터는 관리가 힘들었기에 관리를 전담할 어떤 장치를 만든 것이다.
2-1. Shared Pointer
스마트 포인터의 종류로는 크게 3가지가 있지만, 가장 많이 사용되는 「shared_ptr」에 대해 먼저 알아본다.
shared_ptr의 대략적인 구조는 아래와 비슷한다.
class RefCountBlock
{
public:
int _refCount = 1;
};
template<typename T>
class SharedPtr
{
public:
SharedPtr() {};
SharedPtr(T* ptr) : _ptr(ptr)
{
if (_ptr != nullptr)
{
_block = new RefCountBlock();
std::cout << "RefCount : " << _block->_refCount << std::endl;
}
}
~SharedPtr()
{
if (_ptr != nullptr)
{
_block->_refCount--;
std::cout << "RefCount : " << _block->_refCount << std::endl;
if (_block->_refCount == 0)
{
delete _ptr;
delete _block;
std::cout << "Data Deleted." << std::endl;
}
}
}
public:
T* _ptr = nullptr;
RefCountBlock* _block = nullptr;
};
shared_ptr은 참조 횟수를 기록할 카운트 블록을 갖고 있다. 카운트가 1 이상인 이상 계속 살아있다.
기존의 포인터를 받아 생성자를 호출하는데, 받은 포인터가 nullptr이 아닐 경우 새로운 블록을 생성하여 관리에 들어간다.
소멸자 호출 시엔 블록의 참조 카운터를 1씩 깎는다.
카운터가 0이 아니라면 데이터를 다 지우는 부분은 건너뛰게 된다.
int main()
{
SharedPtr<Player> p1(new Player());
return 0;
}
메인을 이렇게 작성 후 실행하면 아래와 같은 결과가 나온다.

정상적으로 생성자가 호출되고 카운트가 상승했다.
이후 소멸자가 호출되고 카운트가 0이 된다.
카운트가 0이 됐으므로 모든 데이터를 삭제하고 소멸했다.
이래서야 일반 포인터와 다를 게 없으므로 카운트를 더 올려보자.
클래스에 아래의 코드를 추가한다.
SharedPtr(const SharedPtr& sPtr) : _ptr(sPtr._ptr), _block(sPtr._block)
{
if (_ptr != nullptr)
{
_block->_refCount++;
std::cout << "RefCount : " << _block->_refCount << std::endl;
}
}
void operator=(const SharedPtr& sPtr)
{
_ptr = sPtr._ptr;
_block = sPtr._block;
if (_ptr != nullptr)
{
_block->_refCount++;
std::cout << "RefCount : " << _block->_refCount << std::endl;
}
}
main()의 내용을 아래와 같이 작성한다.
SharedPtr<Player> p2;
{
SharedPtr<Player> p1(new Player);
p2 = p1;
}이 코드를 통해 p1 사라진다고 해도 p2에 의해 객체 자체는 바로 사라지지 않음을 확인할 수 있다.
아래는 위 코드의 실행 결과이다.
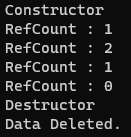
p2 = p1의 대입 연산자가 실행됨에 따라 _refCount가 증가해 2가 되었다.
영역이 끝나면서 p1은 사라지지만 카운트가 0이 아니므로 데이터 자체는 삭제하지 않고 카운트만 감소시킨다.
이후 main이 종료되면서 1이었던 카운트를 감소시켜 0으로 만들고 모든 데이터를 삭제하게 된다.
shared_ptr을 사용함으로써 프로그래머는 명시적으로 객체를 삭제해 줄 필요가 사라졌다.
아무도 참조하지 않을 때 프로그램이 알아서 데이터를 정리해 주기 때문이다.
이제 흉내를 낸 것이 아닌 진짜 shared_ptr을 사용해 보자.
먼저 Player 클래스의 「Player* _tgt = nullptr」을 「std::shared_ptr<Player>_tgt = nullptr」로 바꾼다.
그리고 main()의 내용을 아래와 같이 바꾼다.
int main()
{
std::shared_ptr<Player> p1 = std::make_shared<Player>();
{
std::shared_ptr<Player> p2 = std::make_shared<Player>();
p1->_tgt = p2;
}
p1->Attack();
return 0;
}블록을 만들고 그 내부에 p2를 생성시키고, p1의 _tgt가 p2를 참조하도록 했다.
그리고 shared_ptr이 정상적으로 동작하는지 확인하기 위해 p1의 Attack()을 실행시키도록 했다.
먼저 중단점을 걸어 p2 객체가 살아있는지 확인한다.

조사식을 통해 p1->_tgt를 보면 참조한 객체가 잘 살아있음을 볼 수 있다.

콘솔창을 보면 HP에 이상한 값이 들어온 게 아니라 정상적으로 90이 출력됨을 볼 수 있다.
shared_ptr이 부정 메모리 참조를 제대로 방지해 줬다 할 수 있다.
2-2. Weak Pointer
앞에서 Shared Pointer에 대해 살펴봤는데, 정말 좋은 기능이지만 포인터의 근본적 문제를 해결해 주진 않는다.
p1과 p2가 서로를 참조한다고 생각해 보자.
원래 프로그램이 종료될 때 모두 소멸자를 통해 소멸 후 종료하게 되는데, shared_ptr을 통해 서로 참조하고 있으면 프로그램이 종료될 때까지 소멸되지 않고 남아있게 된다.
프로그래머가 서로 참조한다는 것을 인식하고 종료 전 nullptr를 사용해 참조를 해제시켜 해당 문제를 방지할 수도 있지만, 매우 번거로운 작업이 될 수 있다.
Weak Pointer는 그런 문제에 대한 하나의 해결책이 될 수 있는 기능이라 할 수 있다.
다시 아까 만들었던 Shared Pointer의 모사 클래스로 돌아가 보자.
먼저 「std::shared_ptr<Player>_tgt = nullptr」 「std::weak_ptr<Player>_tgt」로 바꾼다.
여기에 weak_ptr이라는 개념이 등장하게 되면서 카운트 블록은 다음과 같이 변한다.
class RefCountBlock
{
public:
int _refCount = 1;
int _weakCount = 1;
};_weakCount가 추가된 것을 볼 수 있다.
_refCount는 이전과 같이 객체를 참조하는 것이 몇 개인지를 나타내고,
_weakCount는 다른 weak_ptr이 객체를 참조하는 개수를 나타낸다.
그리고 이전엔 _recCount가 0이 되면 블록도 다 삭제했는데 이젠 그렇지 않다.
~SharedPtr()
{
if (_ptr != nullptr)
{
_block->_refCount--;
std::cout << "RefCount : " << _block->_refCount << std::endl;
if (_block->_refCount == 0)
{
delete _ptr;
// 블록은 남겨두게 된다
//delete _block;
std::cout << "Data Deleted." << std::endl;
}
}
}블록을 살려두어야 weak_ptr을 통해 해당 메모리가 날아갔는지 아닌지 확인할 수 있기 때문이다.
weak_ptr은 객체의 생명주기에 직접적으로 관여하진 않지만, 객체의 생사를 확인하는 용도로 사용된다.
이제 Attack()을 확인해 보면 에러가 떠 있는 것을 확인할 수 있다.

weak_ptr은 shared_ptr처럼 바로 사용할 수는 없다. 사용하기 전에 이 포인터가 정말 살아있는지 확인할 필요가 있다.
expired()라는 함수를 통해 포인터의 생사 여부를 확인하고, 살아있다면 lock()을 통해 실제로 사용할 수 있는 shared_ptr 형태로 변환해 비로소 사용할 수 있게 된다.
수정된 코드는 아래와 같다.
void Attack()
{
if (_tgt.expired() == false)
{
std::shared_ptr<Player> sPtr = _tgt.lock();
sPtr->_hp -= _dmg;
std::cout << "Target's HP : " << sPtr->_hp << std::endl;
}
}
weak_ptr을 사용하면 객체의 생명주기에서 보다 자유로워질 수 있다는 장점이 존재하지만
단점으로는 객체를 명시적으로 확인[ expired() ]하고 shared_ptr로 변환[ lock() ]해 주어야 하기 때문에 번거로워진다는 점을 꼽을 수 있다.
개발을 할 때 메모리 구조에서 자유로워질 것인지, 코드 작성에 있어서의 편리함을 택할 것인지 선택이 필요하게 된다.
이제 실제 weak_ptr의 동작을 확인해 보자.
int main()
{
std::shared_ptr<Player> p1 = std::make_shared<Player>();
{
std::shared_ptr<Player> p2 = std::make_shared<Player>();
p1->_tgt = p2;
p2->_tgt = p1;
}
p1->Attack();
return 0;
}p2를 블록으로 묶어 소멸되게 만들었다.
p2가 소멸되었기 때문에 expired()의 값은 true가 돼서 검사를 통과하지 못할 것이다.
중단점을 걸어 확인해 보자.
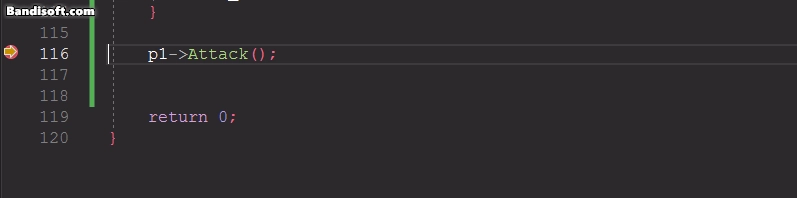
객체가 이미 만료(expired)되었기 때문에 조건문 안으로 들어가지 못하고 그냥 빠져나와 버린다.
main()에서 블록을 떼고 다시 실행하면 정상적으로 조건문 안으로 들어가게 된다.
2-3. Unique Pointer
Unique Pointer는 이름은 이름에서 유추할 수 있듯이 어떤 포인터를 독점하는 포인터이다.

위 이미지처럼 바로 넘겨주려고 하면 에러가 생기게 된다.
꼭 옮겨야 할 때는 std::move()를 통해 rvalue 이동으로 넘겨주어야만 한다.
unique_ptr은 내부적으로 참조 카운트가 없기 때문에 기존의 포인터를 활용하는 것과 매우 비슷하지만,
거기서 복사에 관한 부분만 막아놓은 형태라고 볼 수 있다.
3. 마무리
C# 등의 GC 언어에선 알아서 메모리를 정리해 주는 것을 보면 확실히 편리하다는 생각이 든다.
그럼에도 C++ 이 여전히 많이 사용된다는 것은 그만큼 로우레벨에 대한 접근성이 좋기 때문이 아닐까.
프로그래밍에 대해 더욱 잘 이해하기 위해서는 로우레벨에 대한 더욱 깊은 이해가 필요함을 항상 느낀다.
'Study > C++ & C#' 카테고리의 다른 글
| [C++] Select Model (0) | 2023.06.12 |
|---|---|
| [C++] STL : Vector (0) | 2023.04.18 |
| [C++] 다중 포인터 (0) | 2023.01.27 |
| [C++] 포인터 기초 (0) | 2023.01.26 |
| [C#, Python] C# 라이브러리를 이용한 discord.py 봇 개발 (2/2) (0) | 2023.01.15 |