눈에 딱 들어온 것이 STL이었기 때문에 STL부터 복습했다.
1. Vector의 원리
Vector는 단순히 말하면 동적 배열이다.
기존의 배열은 유동적으로 사이즈를 늘리기 번거로웠는데, 이를 간편하게 해 준다.
벡터는 아래와 같이 동작한다.
- 여유분을 두고 메모리 할당
- 부족할 시 추가로 할당
- 해당 영역에 추가 할당할 수 있으면 할당
불가능할 시 다른 영역에 데이터를 복사해 할당
아래의 코드로 확인해 보자.
vector<int> v1;
// 1. 여유분을 두고 메모리 할당
// 2. 부족하면 추가 할당
for (int i = 0; i < 100; i++)
{
v1.push_back(i);
if ((i % 10) != 0 || i == 0)
cout << v1.size() << " : " << v1.capacity() << " // ";
else
cout << endl;
}위 코드는 지속적으로 데이터를 Push 하면서 Size와 Capacity를 확인한다.
실행 결과는 아래와 같다.

Capacity가 늘어나는 것이 보일 것이다. Vector는 이렇게 알아서 배열의 사이즈를 늘려준다.
여기서 Capacity가 늘어나는 것을 잘 보면 어떤 규칙성을 발견할 수 있다.
1 2 3 4 6 9 13 19 28 42 ... 이렇게 늘어나는 것을 볼 수 있는데, 1.5배씩 늘어난다는 사실을 확인할 수 있다.
벡터는 추가 할당이 필요한 경우 기존 Capacity의 용량의 1.5배의 용량이 되게 하여 추가로 메모리를 할당받는다.
만약 추가로 할당할 공간이 없다면 다른 메모리 영역에 1.5배의 영역을 할당한 후,
기존 데이터를 전부 복사해 오는 형태로 추가 할당을 진행한다.
2. Iterator
「벡터엔 포인터가 있는데, 그냥 for문으로 순회하면 되지 않나?」
라고 생각할 수 있다. 사실 맞는 말이다.
벡터는 무조건 데이터들이 빈칸 없이 연속해 있기 때문에 일반 배열처럼 포인터로 접근해도 아무런 문제가 없다.
하지만 이터레이터는 벡터뿐만이 아니라 다른 자료구조에도 쓰이고, 혹시 모를 부정 메모리 접근을 예방해 준다.
어차피 자료구조를 벡터만 쓰는 일도 없으니 이터레이터에 익숙해져 보자.
이터레이터는 포인터와 매우 유사한 개념이고, 내부적으로 포인터를 가지고 있다.
이를 확인하기 위해 먼저 10의 size를 가지는 벡터를 만들어서 포인터와 비교해 보자.
vector<int> v2(10);
for (int i = 0; i < v2.size(); i++)
{
v2[i] = i;
}
vector<int>::iterator it;
int* ptr;
it = v2.begin();
ptr = &v2[0];
cout << *it << endl;
cout << *ptr << endl;
실행 결과로 둘 다 0을 출력했다.
v2.begin()과 &v2[0]이 같은 값을 가리키고 있다는 것을 알 수 있다.
it는 포인터 변수가 아닌데 어떻게 *연산자로 값을 불러올 수 있었는지 궁금할 수 있다.
이는 벡터의 헤더파일을 내용을 보면 확인할 수 있는데, 그 내용은 아래와 같다.
_NODISCARD _CONSTEXPR20 reference operator*() const noexcept {
#if _ITERATOR_DEBUG_LEVEL != 0
const auto _Mycont = static_cast<const _Myvec*>(this->_Getcont());
_STL_VERIFY(_Ptr, "can't dereference value-initialized vector iterator");
_STL_VERIFY(
_Mycont->_Myfirst <= _Ptr && _Ptr < _Mycont->_Mylast, "can't dereference out of range vector iterator");
#endif // _ITERATOR_DEBUG_LEVEL != 0
return *_Ptr;
}고급 문법으로 떡칠되어 있어서 머리가 아플 수도 있지만, 우린 이터레이터가 *연산자를 사용하기 위해
연산자 오버로딩을 사용해서 이터레이터 내부의 _Ptr의 값을 리턴하게끔 코드가 짜여 있다는 것을 확인할 수 있다.
begin()이 있으면 end()도 있어야 한다.
다음의 코드로 동작을 확인해 보자.
vector<int>::iterator itBegin = v2.begin();
vector<int>::iterator itEnd = v2.end();
for (auto it = itBegin; it != itEnd; ++it)
{
cout << *it << endl;
}중단점을 걸고 itBegin의 포인터와 itEnd의 포인터의 위치를 확인해 보자.
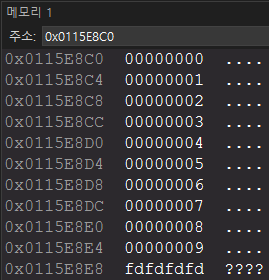
메모리에서 보면 0부터 9까지 잘 들어간 것으로 보인다.
begin()이 배열의 첫 원소를 가리켰으니 end()는 끝 원소인 9를 가리킬 것이라 생각할 수 있다.
실제로 end()의 포인터가 어디를 가리키는지 확인해 보자.

분명히 9를 가리켜야 하는데 -33686019라는 이상한 값을 나타낸다.
이는 에러가 난 것이 아니다!
end()는 마지막 원소의 바로 다음을 가리키기 때문에 일어나는 현상이다.
메모리 뷰에서 9 다음에 보이는 fdfdfdfd가 보이는가? 저기를 end()가 가리킨다.
이에 대해 이해하고 이터레이터를 사용해야만 하겠다.
3. 삽입/삭제 및 임의 접근
벡터를 쓰다 보면 중간에 데이터를 삽입하거나 삭제를 해야 할 일이 생길 수도 있다.
없는 게 제일 좋지만 사람 일은 알 수가 없다.
벡터는 연속적으로 데이터가 저장된다고 한 사실을 기억하는가?
중간에 삽입하거나 삭제하면 늘어난 만큼 또는 줄어든 만큼 뒤의 원소들을 당기거나 밀어야 한다.
벡터의 사이즈가 작다면 큰 오버헤드라고 할 수 없지만 사이즈가 수백만 수천만이라면?
말 그대로 재앙이라 할 수 있겠다.
그래도 해야겠다면 아래의 코드를 통해 할 수 있다.
// 중간 삽입
vector<int>::iterator inIt = v2.insert(v2.begin() + 2, 99);
// 중간 삭제
vector<int>::iterator erIt = v2.erase(v2.begin() + 2);
// 중간 일정 구간 삭제
vector<int>::iterator erIt = v2.erase(v2.begin() + 2, v2.begin() + 4);아... 이건 너무 귀찮다. 꼭 이렇게 귀찮게 만들어야 했을까? 라고 생각할 수도 있다.
이는 벡터에서의 중간 삽입/삭제가 매우 비효율적인 작업임을 인지하고 사용하라는 경고 및 확인 작업이라 할 수 있다.
그리고 erase()엔 구간 삭제도 있는데, 여기서 주의할 점이 있다.
위 예시 코드에선 3번째 원소에서 5번째 원소까지를 구간으로 잡아놨는데, 이는 3번째 원소부터 5번째 원소까지 다 지우라는 의미는 아니다.
위 코드 대로라면 3번째와 4번째 원소만 삭제한다. 뒤에 오는 인자는 「이 원소 앞까지만 지워야 해」라고 말하는 것이다.
임의 접근은 벡터가 배열의 형태로 연속적으로 데이터가 저장되어 있기 때문에 가능하다.
만약 중간중간 비어있어서 엉뚱한 메모리를 참조해 버린다면 여간 보통 문제가 아니게 될 것이다.
위를 활용하여 벡터를 순회하면서 특정 데이터만 지우는 코드를 작성해 보자.
// 벡터를 순회하면서 특정 데이터를 전부 삭제하고 싶을 때.
for (vector<int>::iterator it = v2.begin(); it != v2.end(); ++it)
{
int data = *it;
if (data == 3)
{
// 이터레이터의 정보가 싹 날아가서 오류가 생긴다.
v2.erase(it);
}
}it++가 아니라 ++it로 작성한 이유는 전위 연산자를 사용하는 것이 조금 더 효율적이기 때문이다.
벡터의 헤더를 보면 다음과 같이 연산자 오버로딩이 작성되어 있다.
_CONSTEXPR20 _Vector_iterator& operator++() noexcept {
_Mybase::operator++();
return *this;
}
_CONSTEXPR20 _Vector_iterator operator++(int) noexcept {
_Vector_iterator _Tmp = *this;
_Mybase::operator++();
return _Tmp;
}전위연산자는 바로 포인터의 위치를 옮겨 사용한다.
후위연산자는 복사를 뜬 후 그 복사본을 리턴하는 구조이기 때문에 전위연산자를 사용하는 것이 조금 더 효율적이다.
다시 돌아와서 위 코드를 그대로 실행하면 다음과 같은 결과를 확인할 수 있다.

메모리 액세스 위반 예외가 생긴다. 왜 에러가 생기는 것일까?
이 문제는 이터레이터의 구조에 대해 알고 있어야 해결할 수 있다.

이터레이터엔 포인터뿐만 아니라 _Myproxy라는 녀석이 있는데
이터레이터가 어느 벡터에 종속되어 있는지를 나타낸다고 생각해도 지금은 아무 문제가 없다.
erase()는 이터레이터를 없애버리기 때문에,
v2.erase(it)가 실행되면서 기존 it의 _Myproxy를 nullptr로 만들어 버려 메모리 위반 문제가 생긴 것이다.
이를 해결하기 위해서는 이터레이터가 죽지 않게 해 줘야 한다.
erase()는 실행되면서 이터레이터를 리턴하기 때문에 이를 받아주는 형태로 고치면 이렇게 된다.
it = v2.erase(it);이러면 메모리 위반 예외도 없이 잘 실행된다.
하지만 이것도 진짜 해결 방법은 아니다.
erase()가 동작한 후 이터레이터의 포인터는 삭제된 원소가 원래 있던 포인터를 가리키게 된다.
이렇게 되면 삭제된 원소의 자리에 간 데이터는 확인하지 않고 다음으로 넘어가 버린다는 문제가 생긴다.
그 원소도 만약 3이어서 삭제해야 하는 데이터였다면 문제가 생기는 것이다.
이는 매우 간단히 해결할 수 있다.
확인하지 않고 넘어가는 것이 문제라면 조건부로 다음으로 넘어가게 만들면 된다.
// 벡터를 순회하면서 특정 데이터를 전부 삭제하고 싶을 때.
for (vector<int>::iterator it = v2.begin(); it != v2.end();)
{
int data = *it;
if (data == 3)
{
// 삭제한 후 다시 이터레이터를 받아준다
it = v2.erase(it);
}
else
{
// 삭제할 데이터가 아니라면 패스
++it;
}
}위와 같이 ++it를 떼서 조건문에 붙여놨다.
이러면 삭제된 후 당겨져 온 데이터를 확인하지 못하고 지나칠 일 없이 모든 원소를 체크할 수 있다.
4. 기타 Iterator
사용 빈도는 적지만 그래도 필요할 때가 있는 이터레이터가 있다.
const와 reverse 이터레이터인데 아래와 같이 사용할 수 있다.
// const iterator
// 읽기 전용에 유용
vector<int>::const_iterator cit = v2.cbegin();
// reverse iterator
// 거꾸로 읽어나감
vector<int>::reverse_iterator rit = v2.rbegin();const는 말 그대로 상수처럼 굴릴 수 있다.
혹시 모를 데이터 오염에 대비해 읽기 전용이 필요할 때 사용할 수 있겠다.
reverse도 말 그대로 기존 이터레이터를 거꾸로 뒤집은 형태라 할 수 있다.
데이터의 끝부분부터 읽어 나가기 때문에 사용 빈도가 많지는 않다.
5. 마무리
STL은 확실히 많이 쓰이지만, 왠지 모르게 잊어버려서...
이와 관련해서 몇 개 더 공부하고 Modern C++ 쪽을 복습할 듯하다.
'Study > C++ & C#' 카테고리의 다른 글
| [C++] WSAEventSelect Model (0) | 2023.06.14 |
|---|---|
| [C++] Select Model (0) | 2023.06.12 |
| [C++] 스마트 포인터 (0) | 2023.02.04 |
| [C++] 다중 포인터 (0) | 2023.01.27 |
| [C++] 포인터 기초 (0) | 2023.01.26 |