어떻게 합격하여 이렇게 합격 후기를 작성하게 됐다.
필기는 어찌 한방에 합격했지만 실기는 그렇게 자신이 있진 않았다.
필기에서 공부한 개념들을 실기에서 내가 제대로 코드로 쓸 수 있을까? 라는 의문이 있었기 때문.
그래도 합격했으니 참으로 다행이라고 생각한다.
점수

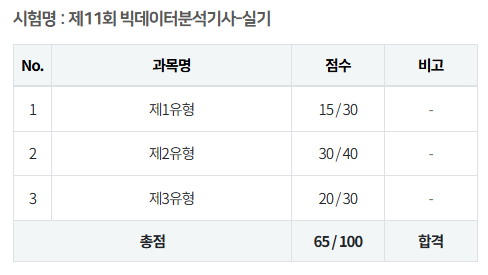
잘 난 점수는 아니지만...
합격했다는 것이 중요하다!
배경
빅데이터분석기사 공부 시작 전 나의 상황
1. 컴퓨터공학 전공
2. 파이썬으로 필요한 프로그램 작성해 활용한 경험 有
3. 통계 문외한
- 학부 때 통계과목 1학기 수강
그냥 코드 작성에만 좀 익숙한 완전한 노베이스 상태였다.
사용한 교재
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=343937260
2025 이기적 빅데이터분석기사 필기 기본서 | 2025 이기적 빅데이터분석기사 | 나홍석 외
최신 출제기준을 적용한 도서로, 빅데이터분석기사 필기 시험의 출제 경향을 철저히 분석하여 수험생들이 혼자서도 학습할 수 있도록 한 완벽 대비서이다. 시행처인 한국데이터산업진흥원에서
www.aladin.co.kr
필기 교재와 실기 교재를 같이 구매했다.
이 교재를 통해서만 "혼자" 공부했다.
다른 교재나 강의를 구매하지 않았다.

반년을 함께한 이기적 교재로만 해결이 다 됐다!
공부 방법
필기
기간
실제 공부 기간은 1달 정도.
하루에 2시간 정도 공부했다.
시간을 딱 정해서 공부한 게 아니라, '어느 파트까지 오늘 하겠다'라는 기준을 잡고 진행한 것이다.
어떤 날은 그 기준을 크게 잡아, 하루에 8시간 이상 공부하는 때도 있었다.
방법
1회독은 그냥 쭉 진행한다.
아무것도 모르는 상태이므로 끝까지 보면서 얕게나마 기억할 수 있게 한다.
이때, 자기가 뭐에 강하고 뭐에 약한지 어느 정도 인식할 수 있다.
1회독을 마치고 기출이나 모의고사를 1 ~ 2회라도 풀어보며 다시 강점과 약점을 점검한다.
2회독부터 약점 위주로 공략한다.
나의 경우는 2, 3파트가 약점이었는데, 실제로 수식을 적용해 계산하는 파트에서 수식이 기억이 안 나 어려웠고,
머신러닝에 대해 너무 얕고 부정확하게 알고 있는 것들이 독이 되는 부분이 있었기 때문이다.
2회독 이후, 남은 기출과 모의고사를 계속 풀며 깎아나간다.
찍어서 맞춘 문제, 긴가민가했던 문제나 틀린 문제들은, 다음처럼 해당 개념이 책의 몇 페이지에 나와있는지 체크하고 넘어갔다.

강점이 계속 강점일 수 있게 하고, 약점을 계속 보완하며 최종적으로 깎아나간다.
교재에 필기 기출은 물론, 충분한 양의 모의고사가 수록돼 있었다고 생각한다.
https://cbt.youngjin.com/exam/index.php?no=69
이기적 CBT, 영진닷컴
빅데이터분석 기사 필기 답안 표기란 과목명 문항수 합격점수 1 과목 빅데이터 분석기획 20개 60점 2 과목 빅데이터 탐색 20개 60점 3 과목 빅데이터 모델링 20개 60점 4 과목 빅데이터 결과 해석 20개
cbt.youngjin.com
영진닷컴이 제공하는 CBT도 시험 1 ~ 2일 전에 활용했다.
단, 문제 가짓수가 많지 않으므로 너무 많이 활용하는 것은 진짜 실력을 확인하기 어려워질 수 있으므로 지양하는 것이 좋다.
4번 정도까지만 활용하는 것이 좋다고 생각한다.
평가
11회 필기는 2, 3파트가 확실히 어려웠다.
생소한 내용이 많았지만, 공부한 내용도 나왔기 때문에,
개념을 확실히 알고 간다면 충분히 합격을 노릴 수 있다고 생각된다.
계산 문제의 비중이 크지 않기 때문에 기조가 유지된다면,
좀 더 암기에 집중하는 것도 괜찮은 것 같다.
나와 같은 비전공자들은 더 많은 시간을 투자해야 하기 때문에 시간이 매우 부족하다.
공부할 내용이 많고, 유사한 개념들이 많이 등장해 매우 헷갈리게 된다.
나는 조금 급해서 공부를 제대로 못했는데, 2달 정도면 충분한 안전마진인 것 같다.
특히 이번 11회 필기에서 책에서 본 적 없는 개념이 등장했다.
그 문제를 딱 봤을 때의 당혹감이란...
앞으로의 시험 기조에 대한 힌트를 던졌다는 느낌이 든다.
RPG로 비유해 보자면, "모르면 죽어야지" 식의 패턴과 같다.
이런 것까지 완벽하게 공부하기가 어려울 것이다.
하지만, 이번 시험처럼만 나오게 된다면 책에 있는 개념을 확실히 공부하면 문제없을 것이다.
저도 그러한 문제들은 찍고 넘겼기 때문에 우리가 공부한 부분을 더 깊게 파고들면 합격으로 이어진다고 생각한다!
아무리 "모르면 죽어야지"식의 문제가 나온다 한들, 숫자가 많지 않을 것이기 때문이다.
실기
기간
실기도 필기와 유사하게 한 달 정도 공부했다.
공부 구간을 정하고 평균 1 ~ 2시간 정도 공부했다.
부족한 파트를 볼 때는 6 ~ 8시간을 볼 때도 있었다.
방법
1회독은 그냥 쭉 본다.
필기에서 했던 것처럼 얕게라도 기억하게 한다.
N회독은 진행하지 않았는데, 실기 특성상 개념에 대한 N회독은 무의미하다고 생각했기 때문이다.
대신 바로 기출을 풀어보기로 했다.
처음 몇 개의 문제들은 오픈북을 한다는 느낌으로 앞의 개념들을 참고하며 풀었다.
이런 식으로 진행하며 어떤 파트에선 어떤 유형이 주로 나오고, 어떤 패턴이 있는지 파악할 수 있다.
슬기로운 통계생활 빅데이터분석기사 커뮤니티에서 제공하는 정보들도 활용했다.
이기적 실기 교재 구매를 인증하면 추가 자료도 제공하는 것이 좋았다.
그리고, 기출 복원이 사람마다 다르게 진행되는 만큼,
검색을 통해 다양한 실기 복원을 확인하고 풀어보는 연습도 진행했다.
유사한 문제라도 미묘하게 달라지는 부분이 있어, 간접적으로 다양한 풀이 유형을 경험할 수 있게 된다.
난 책에 뭘 쓰면서 한 게 아니라, 다음과 같이 에디터에 주석과 함께 작성하면서 공부했다.
이런 식으로 정리하며 공부했다.
예제는 AI를 통해 작성한 예제고, 체험환경에서 제공하는 문제도 풀이를 저장했다.
각 폴더 내용은 이렇게 정리했다.


이런 식으로 정답 스크립트 파일에 주석과 함께 정리했다.
최초에 푼 후 정답을 확인했을 때 내가 작성한 코드보다 좋은 코드였다면,
기존 내 풀이와 함께 그 코드도 가져와 설명을 추가해 그 코드가 왜 좋은 지도 기록했다.
평가
11회 실기는 평이한 난이도였다고 생각한다.
분명 공부한 내용이었는데도 내가 기억하지 못해서 틀려먹은 문제가 좀 많지만...
이번 회차의 실기를 난도가 높다고 하기엔 무리가 좀 있을 것이다.
복기는 다음 커뮤니티에 잘 돼 있으니 참고한다.
https://lab.statisticsplaybook.com/portal/space/bigbungi/post/i-oe-11isoe-e-e-i-i-e-i-e-i-i-e
슬통LAB - 데이터분석, 통계 커뮤니티
복기 남기고 슬통 할인쿠폰 & 스벅 기프티콘 받자! 안녕하세요, 슬통연구소 빅데이터 분석기사 커뮤니티 운영진입니다. 시험 보시느라 정말 수고 많으셨습니다! 이번 시험에 어떤 문제가 나왔는
lab.statisticsplaybook.com
1유형
1. 온실가스 데이터
연도별 온실가스 배출량 1위 국가를 구하는 문제였는데,
바로 구하는 방법을 기억해내지 못해 억지로 패턴 매칭 코드를 작성해 답을 도출했었다.
이후에 어떤 값의 최댓값을 구하는 부분은 간단하게 진행됐다.
2. 결측치를 대체하고 지정된 값을 구하는 문제
``SimpleImputer``를 사용해 결측치를 처리했다.
3. 거래 데이터 처리
이 문제에서 단 한 곳만 제외하고 나머지 코드는 다 맞게 작성했다.
거래가 취소한 건의 거래액에는 -1을 곱해 음수로 만드는 문제였는데,
``loc``을 안 쓰고 무식하게 음수로 만드려고 하니 동작하지 않았다.
Df[df['canceled'] == True]['amount] = - (df['canceled'] == True]['amount])이런 식으로 하니까 당연히 동작하지 않는다.
Pandas에선 이러한 체인 인덱싱을 사용해 슬라이싱 후 값을 할당하려고 하면 문제가 생긴다.
``df[df['canceled'] == True]``는 원본 DataFrame df의 복사본(Copy) 일 수도 있고, 뷰(View) 일 수도 있다.
Pandas는 이를 보장하지 않는다.
두 번째 인덱싱 ``(['amount'] = ...)``에 값을 할당하려고 할 때,
Pandas는 할당 대상이 원본 df의 복사본인지 뷰인지 알 수 없으므로,
사용자에게 경고(SettingWithCopyWarning)를 발생시키며 원본 데이터가 변경되지 않을 위험이 있다.
만약 첫 번째 인덱싱 결과가 복사본이었다면, 그 복사본에만 값을 할당하게 되고, 원본 df는 전혀 변경되지 않는다.
이는 ``loc``을 통한 명시적 인덱싱으로 해결해야 한다.
# 'canceled'가 True인 행의 'amount' 열에만 -1을 곱하여 할당
df.loc[df['canceled'] == True, 'amount'] = -df['amount']
분명 공부한 내용이고, 신경 써서 몇 번 확인했던 내용인데도 떠올리지 못해서 틀려버리고 말았다.
``loc``을 사용해야 하는 문제는 계속 나올 가능성이 높다고 생각하므로, 확실히 공부해 두는 것이 좋겠다.
2유형
2유형에 대해선 난 다음의 전략을 사용했다.
"그리드 서치 같은 짓 하지 말고 RF로만 빠르게 작성하고 다른 문제에 시간을 더 투자하겠다."
난 이 전략에 따라 그리드 서치를 실제로 어떻게 활용할지에 대한 고민을 하지 않았다.
데이터에 결측치도 없어서 그냥 빠르게 ``RandomForestClassifier``를 사용해 간결하게 끝냈다.
난 검증 데이터 분할 없이 기본으로 주어지는 학습 데이터 모두를 학습에 사용했다.
나처럼 그냥 탐색 없이 그냥 랜덤 포레스트를 사용한 사람들은 25점을 받았다고 했는데, 나의 경우는 30점이다.
난 아마 분할 없이 데이터를 그대로 다 써서 그랬던 것일지도 모르겠다.
3유형
선형회귀, 상관계수 등을 구하는 문제들이 있는 곳이다.
다 무난한 문제들이었다.
여기서 ttest 문제를 하나 틀렸다.
매장 홍보 전후의 매출 차이에 대한 계수를 구하는 문제였다.
홍보 전의 평균 고객 당 매출은 35000원이었고, 주어진 데이터는 홍보 후의 고객 별 매출 데이터였다.
따라서 이 문제는 다음과 같은 형태로 풀어야 한다.
import scipy.stats as stats
import pandas as pd
# 예시 데이터 생성
# data = pd.read_csv("data.csv")['purchase_amount']
data = [36000, 37000, 34500, 38000, 35500, 36500, 37500, 34000, 39000, 36000]
# 기존 알려진 평균 (홍보 전)
popmean = 35000
# 1. 정규성 검정 (데이터 수가 적을 경우 수행, n > 30이면 생략 가능하기도 함)
# 귀무가설: 데이터가 정규분포를 따른다.
# p-value > 0.05 이면 정규성 만족으로 간주 -> t-test 진행
stat, p_val_norm = stats.shapiro(data)
print(f"Shapiro P-value: {p_val_norm:.4f}")
# 2. 일표본 t-검정 (One-Sample t-test) 수행
# stats.ttest_1samp(데이터, 비교할_평균)
# 기본값은 양측 검정(two-sided). (단순 차이 확인)
t_statistic, p_value = stats.ttest_1samp(data, popmean)
print(f"T-statistic: {t_statistic:.4f}")
print(f"P-value: {p_value:.4f}")
# 3. 결과 해석 (유의수준 0.05 기준)
if p_value < 0.05:
print("귀무가설 기각: 홍보 후 구매 금액은 35,000원과 유의미한 차이가 있습니다.")
else:
print("귀무가설 채택: 홍보 후 구매 금액은 35,000원과 차이가 있다고 보기 어렵습니다.")주어진 비교 데이터가 평균 하나밖에 없는 상황에서 어떤 걸 써야 할지 제대로 기억하지 못했다.
그래서 난 억지로 평균이 35000인 같은 크기의 배열을 생성해 "독립표본 T-검정"으로 풀었다.
따라서 오답일 수밖에 없었다.
3유형에서 20점을 얻은 것을 보면 다른 2개 문제는 다 제대로 정답을 제시한 것 같다.
실기에서 중요한 것
help()와 dir()의 사용법
나는 VSCode와 같은 자동완성이 지원되는 에디터에서 코드 작성을 연습했다.
그렇기에 연습 과정에서 ``help()``와 ``dir()``라는 함수를 사용할 일이 일절 없었다.
하지만, 시험 환경에선 그런 기능이 일절 없기 때문에 패키지나 함수 이름이 잘 기억이 안 나면,
무조건 저것들로 찾아야 한다.
나도 시험 이틀 정도 전부터 자동완성 없이 문제를 푸는 연습을 했다.
기존에 연습하면서 어떤 패키지가 어디에 있고, 함수 이름이 뭐고 정도는 대강 알았기 때문에 큰 문제는 없었다.
막상 실제 시험장에 가 보니 애매한 경우가 좀 있었는데, 저 함수들로 잘 해결할 수 있었다.
어떤 일이 있어도 이 함수들의 사용은 잘 이해하고 가야 하겠다.
시험 시작 전 환경에서 연습하기
시험 시작이 10시일 때, 9시 30분부터 컴퓨터를 켜고 환경을 점검할 수 있다.
이때 그냥 멍하게 있는 것이 아니라, ``help()``같은 함수들을 사용하며 감각을 익혀야 한다.
패키지들을 불러와서 잘 동작하는지도 확인해 보자.
나도 긴장에 좀 가물가물하다가 저 시간을 활용해서 정신을 좀 차리고 시험장 환경에 적응했던 것 같다.
이 시간에 여러 코드를 작성해 테스트해 보면서 나름대로 준비를 한 것이 꽤 도움이 됐다.
시험 대비 자료 정리
시험 전까지 계속 머리에 넣기 위해 개념 등을 정리한 자료를 AI를 통해 만들었다.
# [기본 데이터 처리]
import pandas as pd
import numpy as np
# [데이터 전처리]
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, MinMaxScaler, StandardScaler
from sklearn.impute import SimpleImputer
# [모델링 & 평가]
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import f1_score, roc_auc_score, accuracy_score, mean_squared_error, r2_score
# [통계 검정 - scipy]
from scipy import stats
stats.ttest_ind, stats.ttest_rel, stats.ttest_1samp # (T-test)
stats.chi2_contingency # (카이제곱)
stats.f_oneway # (ANOVA)
stats.shapiro, stats.kstest # (정규성 검정)
stats.wilcoxon, stats.kruskal # (비모수 검정)
stats.pearsonr # (상관분석)
# [통계 분석 - statsmodels]
import statsmodels.api as sm
from statsmodels.formula.api import ols, logit, glm
# 3-2. 범주형 (최빈값)
# strategy='most_frequent' (최빈값)
imputer_cat = SimpleImputer(strategy='most_frequent')
df[['cat_col']] = imputer_cat.fit_transform(df[['cat_col']])
# [Tip] 모든 컬럼을 한 번에 채우고 싶을 때 (df[:] 사용)
# df[:] = ... 하면 컬럼명/인덱스 유지하면서 값만 교체됨 (매우 유용!)
imputer = SimpleImputer(strategy='mean')
df[:] = imputer.fit_transform(df)
df_train[:] = imputer.fit_transform(df_train)
df_test[:] = imputer.transform(df_test)
# 4. [Expert] 그룹별 결측치 대치 (9회 기출 패턴)
# 예: '학과'별 '성적'의 평균으로 결측치 채우기
# transform('mean')은 그룹별 평균을 원래 데이터 인덱스에 맞춰 확장해줌
df['score'] = df['score'].fillna(df.groupby('major')['score'].transform('mean'))
# 5. 삭제
df = df.dropna()
# 라벨 인코딩 (범주형 -> 수치형)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['category_col'] = le.fit_transform(df['category_col'])
# 원-핫 인코딩 (주의: Train/Test 컬럼 개수 불일치 해결 필수!)
# [Method 1] 자동 변환 (편리함): 문자열(object) 컬럼 자동 감지
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)이런 식으로 내용을 꽉 채운 마크다운 문서를 만들고, ``pdf``로 변환해 폰에 저장 후 시험장까지 이동하며 공부했다.
확실히 정리된 자료가 있으니까 좋았다.
공부하면서 아차 싶었던 것들을 한 곳에 정리해 두니 좀 덜 까먹게 되더라.
단순히 자료 정리뿐만 아니라, 공부하면서도 AI의 덕을 많이 봤다.
단순히 "이렇게 해야 정답이다"가 아니라, "왜 이걸 써야만 하는지"에 대해 까지 자세하게 알려주니 공부하기 매우 좋았다.
후기
얼떨결에 준비하게 된 빅데이터 분석기사, 아는 게 없으니 쉽지 않았다.
달랑 책 두권만 사서 공부해서 다 한방에 합격했으면 가성비가 꽤 좋았던 것 같다.
정말 다 한방에 넘겨서 참으로 다행이긴 하다...
잘 몰랐던 통계 개념들도 공부하게 된 것이 좋은 경험이었다고 생각한다.
시험도 좀 변해야 할 것 같다.
시험이라는 것의 의도에 대해선 충분히 공감하고 이해하지만,
AI까지 등장해 실생활에 깊이 침투한 상황에서 자동완성 같은 것도 사용하지 못하게 하는 것은 아쉽다는 생각이 든다.
터미널 환경에서도 Neovim 같은 것들을 사용해서 편리한 개발을 할 수 있는 시대이다.
TL;DR: 자동완성 정도는 해줘도 되지 않나?
이렇게 정처기에 이어, 빅분기까지 따면서 쌍기사가 됐다.
솔직히 이 필드에서 쌍기사가 얼마나 메리트가 있나 싶지만...
따 둬서 나쁠 건 하나도 없을 것이다.
이걸 계기로 AI와 관련한 일을 하게 될지도 모르고 말이다.
'Study > Others' 카테고리의 다른 글
| 제11회 빅데이터분석기사 필기 짧은 후기 (0) | 2025.09.21 |
|---|---|
| 리눅스 업데이트 미러에 카카오 미러 적용 (0) | 2024.11.20 |
| 봇 배포에 Github Action 적용 (0) | 2024.01.17 |
| [WSL2] 가상 디스크 용량 압축하기 (0) | 2023.02.13 |